SAP HANA Cloud Data Lake Integration with AWS S3 Storage
This is my first blog on SAP Hana Cloud & aims to share my experiences and learnings of SAP HANA Cloud Data Lake so far. In this, I will introduce you to SAP HANA Cloud Data Lake and the scenario I have concocted.
Before going deep into SAP HANA Cloud Data Lake, lets understand little bit about what is Data Lake & where it fits in the data tier.
Data Lake

A data lake is a centralized repository or large container that allows you to store all your structured and unstructured data at any scale.
Data lakes store everything as compared to Data Warehouse which focuses only on Business Processes. You can store your data as-is, without having to first structure the data, and run different types of real-time analytics, and machine learning to guide better decisions.
SAP Hana Data Tier Architecture

- At the top of the pyramid is the most frequently needed data. This data is stored in-memory.
- At the bottom is the raw or archive data. Here lies the data that will only infrequently need to be accessed.
- SAP HANA Cloud’s data lake layer makes sure critical data is available in real time, urgent data available in near-real-time, and important but older data is available as quickly as possible.
Practical
Now lets jump into implementation. We will go through the process of loading data into SAP HANA Cloud Data Lake from AWS S3 storage and once it has been successfully loaded, we will carry out some further processing and querying.
I will be using SAP Hana Cloud& AWS Free trail version account.
Prerequisites
- You should have AWS account with S3 storage setup.
- You should have SAP Hana Cloud account & Sub account.
For this example, we will be using data relating to every Player’s performance in One Day Internationals (ODI) till 2020, for e.g.

Step1. Login to your AWS account & goto S3 Storage

Create a bucket & upload your source data file. I have opted for the GUI upload but in case if you have more number of files you can use S3 Command line Interface (CLI). The upload will be very fast using CLI.
Step2. Login to SAP Hana Cloud instance

Step3. Click on Enter Trail Account -> Select SubAccount -> Select Space
Refer below link to enable DataLake instance.
Step4. Once your Data Lake instance is enabled, goto your Database explorer you should be able to see the default connection to the Data Lake, “SYSRDL#CG_SOURCE”
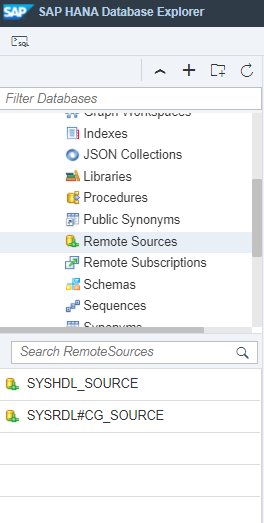
Step5. Create a Physical Table in the Data Lake through the Procedure named “SYSRDL#CG.REMOTE_EXECUTE”
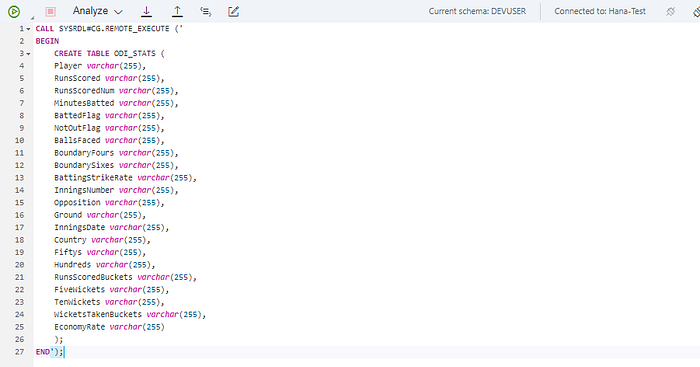
Note that it’s also possible to modify Tables, create Views and Indexes using the above approach. Once the table is created you should be able to see it under Remotes Sources.
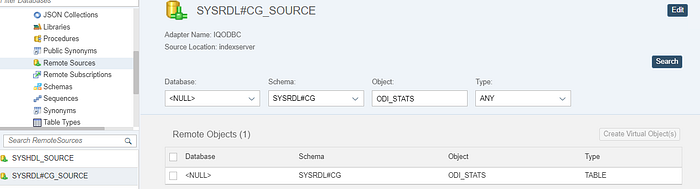
Step6. Now we are ready to load the data into our SAP HANA Cloud Data Lake instance using LOAD TABLE statement.
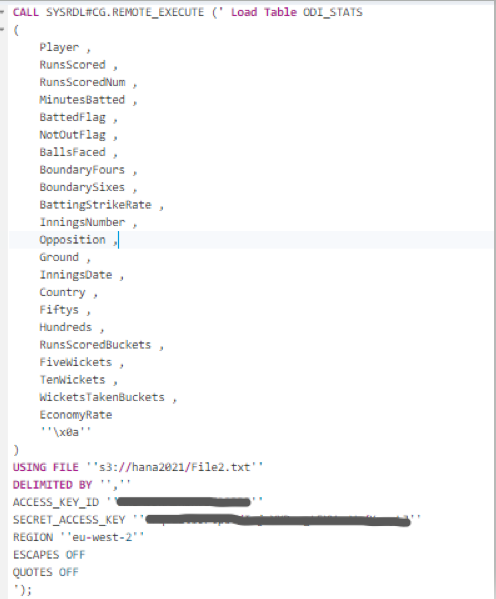
Note that the Access Key, Secret Access Key & the region details retrieved from AWS S3 must be cited here.
Step7. Now the data is stored in SAP Hana instance but to access this data we must now create a Virtual Table. Refer below screenshot to Create Virtual Object
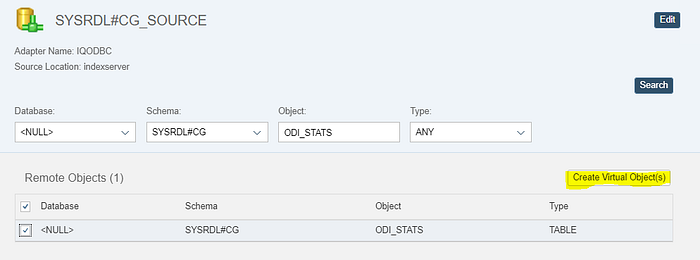
Once the Virtual table is created you should be able to see the data
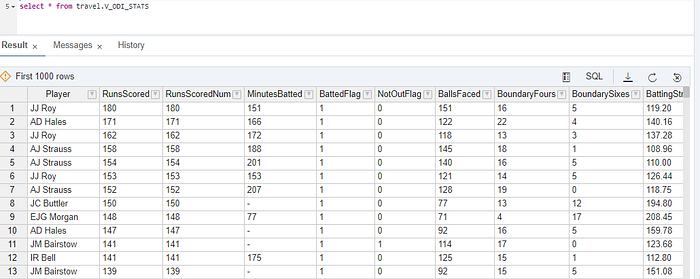
Now you are ready to explore your data & also you can visualise it.
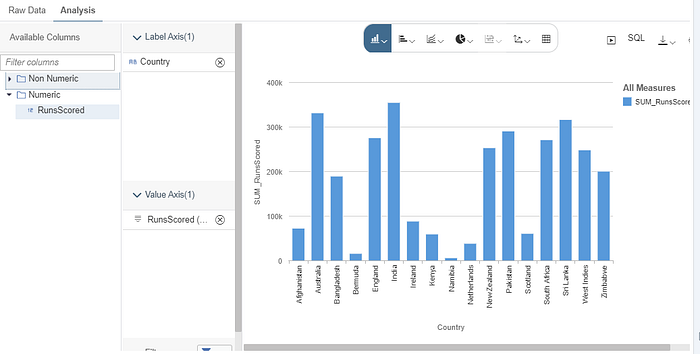
You can combine this with other datasets or create Calculation Views before we consume the resultant data in SAP Analytics Cloud.
I hope this helps you appreciate the basic architectural underpinning of SAP HANA Cloud Data Lake. You can follow the above steps to load and work with any of your own datasets.
Please let me know if there are any questions or insights that you wanted to share.